|
2131| 0

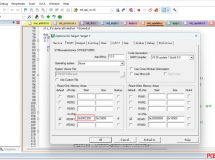
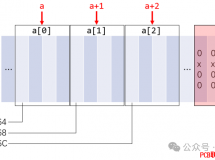
武汉地区嵌入式培训机构_对嵌入式系统中目标识别技术的分析 |
| ||












Copyright ©2015-2022 长沙市凡亿教育科技有限公司 Powered by©Discuz! 技术支持:凡亿教育 ( 湘ICP备2024059722号 )




 窥视卡
窥视卡



 置顶卡
置顶卡 变色卡
变色卡