引言随着深度神经网络(DNNs)在各种应用中变得越来越复杂和普遍,对高效硬件加速器的需求比以往任何时候都更为迫切。在后摩尔定律时代,传统电子加速器面临着基本限制,在带宽和能效方面造成瓶颈。硅基光电子技术应运而生,可为深度学习加速提供节能、超高带宽和低延迟的解决方案。4 B* G% {; f1 @! ^( B
本文介绍CrossLight,新型硅基光电子神经网络加速器,通过跨层设计方法解决光计算中的关键挑战。将探讨光计算的基础知识、CrossLight的架构以及与最先进加速器的性能比较。% K' S. X" I( t+ y& N' {
" D4 O e# `' j光计算基础
# S! B3 N4 o, g2 V' u$ a1 w) B! m在深入了解CrossLight之前,让我们先了解深度学习光计算的基础知识。光加速器通常使用广播和权重(B&W)配置来执行矩阵-矢量乘法,这对DNN中的卷积(CONV)和全连接(FC)层都是必不可少的。+ @. N' p( m, ^! v! g0 @
vndjbb4wr4k6405695118.png
 ) R3 J$ s- v1 ~0 N- R. M2 k8 [
) R3 J$ s- v1 ~0 N- R. M2 k8 [
图1显示了基于非相干广播和权重(B&W)的光电子神经元配置。) F) C1 k: T$ X' ?+ z2 W9 w
在此配置中,输入值通过调制器印刻在不同波长的光上。然后,这些波长被合并并分成多个分支,每个分支由微环谐振器(MRs)加权。加权信号通过光电探测器求和,完成矩阵-矢量乘法运算。7 V5 O+ y0 n5 s7 `; B" y
这种设置中的关键组件是微环谐振器(MR)。MR可以调谐以改变特定波长的能量,有效地在光域中实现乘法运算。5 U5 T6 N* j B$ k
CrossLight架构
0 L( _/ F& o2 }5 w9 b4 Y" tCrossLight采用跨层方法优化光加速,解决设备、线路和架构层面的挑战。' K3 n7 Y% L# g$ z6 v6 h
rcw4xofdo3b6405695218.png
 0 b0 F( @$ \: ~) D( s: W3 O/ R) d
0 b0 F( @$ \: ~) D( s: W3 O/ R) d
图2展示了CrossLight非相干硅基光电子神经网络加速器的高级概述。( a* k% M8 b" D w( u& M7 ]# p
设备级优化在设备级别,CrossLight引入了优化的MR设计,对制造工艺变化(FPVs)更具弹性。通过全面的设计空间探索,研究人员发现,使用400纳米的输入波导宽度和800纳米的环形波导宽度可以将由FPV引起的不期望的谐振波长偏移减少70%。
: r) n& G% m; X* d" w" e6 R$ R线路级优化为解决紧密排列的MR之间的热串扰问题,CrossLight采用了结合热光(TO)和电光(EO)调谐的混合调谐方法。与传统的仅TO调谐方法相比,这种方法可以实现更快的操作速度和更低的功耗。
& B% [) G/ S" z# @( g: c, X# k6 p此外,CrossLight采用了称为热特征分解(TED)的方法,可以集体调谐MR组中的所有MR,有效地以较低的功耗消除热串扰效应。6 C) A) s! R0 Y7 a8 E: ~
a1mbmdzge1b6405695318.png
 $ g# B) I0 h$ X, S7 {/ L
$ g# B) I0 h$ X, S7 {/ L
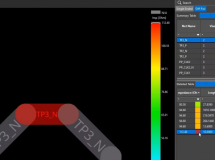
图3显示了10个制造的MR块中相邻MR对之间距离可变时的相位串扰比和调谐功耗。! q" A' v7 s& `4 T
架构级优化CrossLight为CONV和FC层加速引入了单独的矢量点积(VDP)单元,认识到这些层的不同计算需求。这种分离允许更高效地处理这两种类型的层。
~( E8 [0 V# K该架构还在VDP单元内实现了波长重用策略,减少了所需的激光器总数,从而降低了功耗。通过将较大的矢量分解为较小的矢量,并在VDP单元内的多个分支上执行并行计算,CrossLight在并行性和激光器功率需求之间实现了平衡。7 ~# p% ^* E$ G* x4 ~/ I7 G9 _( G# ?6 k
性能分析为评估CrossLight的性能,研究人员使用四个不同复杂度的DNN模型进行了广泛的模拟。( b% |; C6 |, J' ^+ U. F
分辨率分析CrossLight的一个主要优势是能够实现高分辨率计算。虽然一些光加速器限制在2-4位分辨率,但CrossLight可以为其MR组实现高达16位的分辨率。
2 v/ u* R/ u) d. l
ajq0l4vbmzq6405695418.png
 @" o3 W% [/ H0 l: Q: D1 q% A5 O3 ?
@" o3 W% [/ H0 l: Q: D1 q% A5 O3 ?
图4演示了四个DNN模型在权重和激活的量化(分辨率)范围从1位到16位时的推理准确性。3 A. H0 y. x4 g5 h. N# T
这种高分辨率对于维持模型准确性很重要,特别是对于在具有挑战性的数据集上训练的复杂模型。( u. p: W" d4 g+ d1 g( X! K
敏感性分析研究人员进行了敏感性分析,以确定CrossLight的最佳配置,改变CONV和FC层加速器的VDP单元的数量和复杂度。6 X7 f* }8 U' m+ W0 i) _+ T
yipnw3evhz36405695518.png
 ' b9 t$ o$ e0 H) y5 [( q1 j4 z
' b9 t$ o$ e0 H) y5 [( q1 j4 z
图5是散点图,显示了各种CrossLight配置的平均每秒帧数(FPS)与平均每比特能耗(EPB)与面积的关系。* ^3 ^& x$ s: ~( Z# n7 f+ s* N
最佳配置是基于最高的FPS/EPB比率选择的,平衡了性能和能效。
% J/ q9 a/ }5 l! F! \与最先进加速器的比较CrossLight与两个著名的光加速器(DEAP-CNN和Holylight)以及几个电子加速器(包括GPU和CPU)进行了比较。8 W3 p. H1 n) N- y" l. U
mtx404baupp6405695619.png
 * ] Q2 B- J4 ^. d
* ] Q2 B- J4 ^. d
图6比较了CrossLight各变体与光电子和电子加速器平台的功耗。) x0 D; J5 K# A* F( N8 n/ q
结果显示,CrossLight,特别是在优化配置(Cross_opt_TED)中,实现了比其他光加速器和传统CPU/GPU平台更低的功耗,尽管功耗仍高于一些专用电子加速器。
/ O. D, i7 @0 `
. T4 U: |) c% J% @/ @3 \
1gbbpwqp4hk6405695719.png
 6 h; N, A$ E& |& E: h* ^
6 h; N, A$ E& |& E: h* ^
图7比较了光电子DNN加速器的每比特能耗(EPB)值。# Z& z0 n0 G* E* }" ]) T3 a
在能效方面,CrossLight显著优于其他光加速器,平均比DEAP-CNN和Holylight分别低1544倍和9.5倍的EPB。- @" K3 y# X J3 Z- p6 B% L+ x" {+ s
CrossLight的性能优势源于全面考虑了光系统中的各种损耗和串扰,以及在设备、线路和架构层面采用新方法来减轻影响。# n4 t; T* {% t; a# `7 g/ l& g8 s1 K# ^
结论CrossLight展示了光电子神经网络加速器中跨层优化的潜力。通过解决硬件栈多个层面的挑战,与最先进的光电子和电子加速器相比,在能效和每瓦性能方面实现了显著改进。
( Z( B4 D1 h) X# D4 S随着硅基光电子制造工艺的不断成熟,我们可以期待设备调谐成本、损耗和激光器功率开销进一步降低。这一趋势可能会加强光域加速器在深度学习推理任务中的地位。! q4 o6 q# v- E; g- Z4 O% ^
CrossLight的成功突出了在设计下一代硬件加速器时采用全面、跨层方法的重要性。随着我们推动人工智能和机器学习的边界,这种创新架构将在实现更高效和强大的计算系统方面发挥关键作用。1 w( y2 j8 Q% G
参考文献[1]M. Nikdast, S. Pasricha, G. Nicolescu, and A. Seyedi, Eds., Silicon Photonics for High-Performance Computing and Beyond, 1st ed. Boca Raton, FL, USA: CRC Press, 2021.
, v5 `2 \5 @, l+ P- END -
$ X1 n6 v5 J& d9 T5 L' Z% O1 B
- a1 i* _' f9 r Y, V9 f软件申请我们欢迎化合物/硅基光电子芯片的研究人员和工程师申请体验免费版PIC Studio软件。无论是研究还是商业应用,PIC Studio都可提升您的工作效能。+ ^5 P+ v7 G, O/ v3 W
点击左下角"阅读原文"马上申请5 V' t- b' v/ O3 L/ v. [+ ^
1 a. e; l+ L( o: r& d/ b2 x& M欢迎转载6 g- T: G u' b$ G2 j5 w
" G J1 |6 ]! B* h- b8 k2 Q6 h
转载请注明出处,请勿修改内容和删除作者信息!8 O7 X$ \5 I# `& P7 h
& g4 G+ L) c: Y }
, V$ a5 L6 h. M7 [' A/ w& l. S
. `7 x# Z `# s; P( V
i04sdcaxjtp6405695819.gif
 : a6 m. `. U, [) m! [: V
: a6 m. `. U, [) m! [: V
/ d5 h* ~5 O7 p3 v C
关注我们
6 ^* i) A& d3 V. c$ @9 x3 Z4 _: `
# d! }: E x" C! e5 T) y5 X2 _
fhdji2uy4fr6405695919.png
 / u& ]' w( u% R
/ u& ]' w( u% R
|
+ n3 a k5 K l' f3 l/ T. }+ s
toe11bamh4p6405696019.png

6 d8 c9 N2 a( ?0 C/ q9 Z |
' B: p4 F, G3 ~5 ?! u# u7 ?
wyfszhdjarq6405696119.png
 ) q7 N7 X; Y! s4 i) O! g4 J
) q7 N7 X; Y! s4 i) O! g4 J
|
$ G, P9 W1 g! }6 `. p# n6 z C& y% `* U2 R; _, q
q, ~6 `3 O( h# z5 Z. u2 `/ o) e' a4 B
关于我们:
& r4 \* d) _6 y# o- v深圳逍遥科技有限公司(Latitude Design Automation Inc.)是一家专注于半导体芯片设计自动化(EDA)的高科技软件公司。我们自主开发特色工艺芯片设计和仿真软件,提供成熟的设计解决方案如PIC Studio、MEMS Studio和Meta Studio,分别针对光电芯片、微机电系统、超透镜的设计与仿真。我们提供特色工艺的半导体芯片集成电路版图、IP和PDK工程服务,广泛服务于光通讯、光计算、光量子通信和微纳光子器件领域的头部客户。逍遥科技与国内外晶圆代工厂及硅光/MEMS中试线合作,推动特色工艺半导体产业链发展,致力于为客户提供前沿技术与服务。
2 ?, e1 A. e. R) T/ v# b$ @" j$ M9 M
* C6 ~1 K) u; H4 j3 Z* r# K" vhttp://www.latitudeda.com/
0 p5 J, J" j% d# c: k/ _(点击上方名片关注我们,发现更多精彩内容) | 





















 窥视卡
窥视卡
 置顶卡
置顶卡 变色卡
变色卡