
|
317| 0

自动驾驶将驶向何方?大模型(World Models)自动驾驶综述 |
|
匿名
发表于 2024-9-5 12:02:00
|阅读模式

| ||












Copyright ©2015-2022 长沙市凡亿教育科技有限公司 Powered by©Discuz! 技术支持:凡亿教育 ( 湘ICP备2024059722号 )



 置顶卡
置顶卡 变色卡
变色卡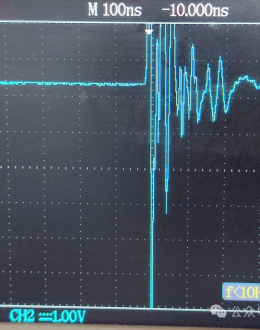




![电源电路中的电磁兼容设计[20250414]](data/attachment/block/24/24fb38c4670aecc3529d4399e5bb4889.jpg)











