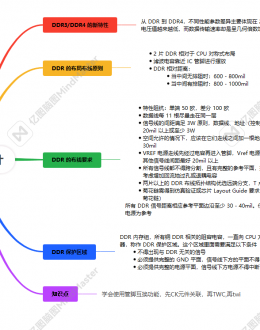
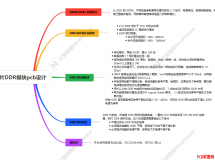
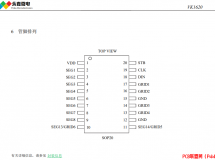
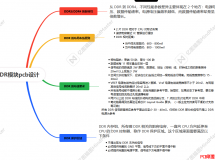
引言
; q3 M: r5 s+ t" Q1 @# }( U; `+ L! D% Y在人工智能领域快速发展的今天,对高效且强大的计算解决方案的需求前所未有地高涨。本文FuriosaAI开发的RNGD张量收缩处理器,这是突破性技术,旨在应对大语言模型(LLMs)和生成式AI时代的可持续AI计算挑战。! P; L7 i& M1 W/ }; ^' D0 @' K
yawrfnvugic64042710159.png
 - {* Z" c4 S! m, S/ a
- {* Z" c4 S! m, S/ a
图1:显示FuriosaAI成立、RNGD开发里程碑和首次LLM演示的时间线。
7 Y5 O m; \' j; F! [5 B/ A8 c( Z: b! {) K# e" B1 u: ]1 t2 ~
RNGD处理器代表了AI加速技术的重大进步。FuriosaAI的使命是"使AI计算可持续,让地球上的每个人都能接触到强大的AI"。为实现这一目标,他们创造了一款在保持能源效率的同时还能提供出色性能的芯片。
, M5 |" w7 u- x5 {3 `- v0 V6 U9 W! D O3 U
让我们深入了解RNGD处理器的主要特性:2 G V. @. _9 s0 h3 y) A& G, m
fa3mtsaanqd64042710259.png

$ K" \9 B. T$ \! ?* z! D/ ~7 Q图2:RNGD处理器的详细规格,包括FLOPS、内存容量和功耗。
' @* K/ E' j* p% q
8 B7 `* J8 P$ l: qRNGD拥有512 TFLOPS的计算能力,这是通过8个处理元件实现的,每个元件能够达到64 TFLOPS(FP8)。处理器配备了48 GB的内存,其中包括256 MB的SRAM,并提供令人印象深刻的384 TB/s片上带宽。借助两个HBM3模块,内存带宽达到1.5 TB/s。' w4 Y5 {' ?$ d5 G, z* b# d5 @
6 r5 r& a) x7 WRNGD的突出特点是能够在150瓦功率范围内处理高性能LLM工作负载。这使得其适用于空气冷却的数据中心,有效解决了AI计算中日益增长的能源消耗问题。
, T* ^* a! k) G W+ ]& I6 C; d, H
l1zgyzhyiam64042710300.png
 ; _8 }* t4 G8 r0 J4 g
; _8 }* t4 G8 r0 J4 g
图3:RNGD芯片架构的详细视图,包括SoC和HBM3组件。. a Q7 z, z+ k8 Y0 `% q
/ I( Q4 ?1 W( Q+ e; W4 p0 M6 w1 GRNGD采用台积电5nm工艺技术,芯片面积为653 mm2,晶体管数量达400亿。芯片设计使用了CoWoS-S(Chip-on-Wafer-on-Substrate with Silicon interposer)封装技术,这种技术允许将SoC与两个HBM3内存堆栈集成在一起。$ `" w! Z+ N8 K& K o: y8 y
& E! W+ ^3 ]: s早期性能数据显示了令人鼓舞的结果:7 q- T" d b7 v. F6 ?/ w) C
pvfpbbxxet464042710400.png

% W t. ~$ T& H2 y0 y5 f f; n图4:比较RNGD与NVIDIA L40S、Intel Gaudi 2和Google TPU v5e性能的表格。$ z% M7 _9 R; R/ M
# _: ^% K' h2 z' Q' O' O3 K& `* i根据这些初步基准测试,在运行GPT-J 6B MLPerf基准测试场景时,RNGD的每瓦性能比NVIDIA L40S高出60%。) A" d) D A% N" V0 `: N7 `) x
' G0 O+ E7 m% t) vRNGD效率的关键在于其创新的张量收缩方法,这是深度学习模型中的核心计算。大多数商用深度学习加速器使用固定大小的矩阵乘法作为原语,而RNGD提高了硬件-软件接口的层次,将整个张量收缩作为原语来加速。
* L3 ?+ A* s1 Q) a+ M) z! V' F
ljkximxkhz364042710500.png

4 J) B E) r; M( W: Q) R" u* I! U图5:图解说明张量收缩是深度学习中的核心计算。& L0 E; M5 _4 K
- w5 r3 e+ {. i0 l, U, O+ f1 c这种方法实现了更高的性能和能源效率,同时提供了支持所有深度学习模型的灵活性。RNGD引入了低级einsum记法作为原语,将张量收缩与显式内存布局和调度相结合。
8 y) y9 I- Z" ^8 m N
uz1ir0nypzi64042710600.png

9 u+ T& C. U2 a图6:说明RNGD如何将整个张量收缩作为单个原语操作处理。
' Z" D0 g [2 N, V, u% v( Z
1 A$ f4 j7 k7 e! K. T( j% yRNGD的架构能够高效地进行计算的空间和时间编排,提高了利用率和效率。这对推理任务尤为重要,因为推理任务的批处理大小可能会有很大变化。
% Z3 P6 R0 N" H
vngatfm4nwh64042710700.png

9 Q& Y& c& s* T图7:RNGD处理器的详细架构图,显示互连网络和处理元件。. F: n5 R& i: }6 D" b0 u! K6 w
" F+ I! e4 A/ S$ m# i
为了支持大型模型的多卡配置,RNGD实现了基于PCIe的芯片间通信。这允许通过直接点对点通信减少卡之间的延迟。- Q# p* h+ {/ v% T
h5m5ogor5ja64042710801.png
 8 S3 Q) ?3 F4 [; [) a% h9 \8 a8 I
8 S3 Q) ?3 F4 [; [) a% h9 \8 a8 I
图8:展示多个RNGD卡与主机CPU之间基于PCIe的通信图。
3 ^2 q& O0 ~% A9 X3 Q, ^
$ P% L# |7 c3 p$ L4 }; I |RNGD还支持SR-IOV(Single Root I/O Virtualization)多实例支持和虚拟化,允许虚拟机使用多达8个虚拟功能。3 s# q% q) U% c7 z3 r2 F
6 t( r, ^8 M0 z- t2 F在软件方面,FuriosaAI开发了全面的LLM软件栈,以充分发挥RNGD硬件的潜力:; Q1 r+ f7 d1 e2 |& _8 M7 U
ljelpdng5ul64042710901.png

7 o+ [* e% W: {9 W图9:Furiosa LLM软件栈的图表,从PyTorch模型到RNGD硬件。 P5 j6 j$ A* U6 Q
- N; l/ Y8 ~7 h8 A* p; H5 A这个软件栈包括PyTorch 2.0集成、支持各种精度格式(FP8、INT8等)的量化工具包、多卡上的张量/流水线/数据并行性、先进的DNN编译器,以及最先进的服务优化。 k+ h; @/ a, L2 H
+ O, W$ x2 {0 J, x1 e/ M: s4 QFuriosa编译器在实现端到端模型效率方面发挥着关键作用:
8 R+ }. p T+ y0 v+ s% d
q1qmkcgr0i164042711001.png

. [) G5 k$ }+ Q0 M- C图10:显示RNGD上优化张量操作的编译过程流程图。( v4 @- ?; e) D* p* h* V
( b7 A( G+ h7 h8 ]: @编译器为给定的降维张量形状找到最佳策略,使用性能和功率估算器来探索策略空间。此外,还执行图级优化,如算子融合和内存分配拆分合并调度。
2 }1 E% _9 z: j* \3 h- |1 [- M: ^. g3 j
为了最大化服务性能,FuriosaAI开发了实现先进优化的服务框架:
8 D7 i# O$ ]8 Q
lsk0024yrx064042711101.png
 % j. ~( n* n- ]. L+ \
% j. ~( n* n- ]. L+ \
图11:Furiosa服务框架图,展示其组件和优化。9 e( M1 Z9 @6 N" A& q" v9 ]
h/ i7 [# M( G* {' ^7 J+ E该框架包括PagedAttention和分块KV缓存管理,利用Furiosa编译器和运行时进行高吞吐量服务,支持连续批处理。
# U% g! f$ B8 l. O% z# ?4 v; \7 j5 m3 t& H% Y% t0 H* k
为了高效量化,FuriosaAI提供了一个端到端的自动化量化工具:
! a. ?7 R7 u1 F Q( R) ]: B
vria2myrbcx64042711201.png

: }/ e9 Z6 h q/ N$ p图12:Furiosa量化器概览,这是自动化的基于图的量化工具。9 Y9 f w5 w8 L* |; p
4 |# X/ \, e K2 J# ]- q Q这个工具使用图模式搜索支持任意定制的LLM模型,并提供各种量化方案,包括BF16、INT8、FP8和INT4选项。# ^0 F* ?4 G9 E& [
: M/ i& F9 j! z% j% p* Z U8 w, U0 P* S+ \RNGD的开发采用了先进的方法和工具:
: r( V2 m9 f& g% p
woxvpvfr1jm64042711302.png
 $ K- p# k! f4 k$ k8 T
$ K- p# k! f4 k$ k8 T
图13:展示RNGD创建过程中使用的先进开发方法的信息图。
2 n5 o: ], }' Q0 F
6 e+ l) `# \! n; V这些包括使用Rust和Chisel等高效语言,基于Kubernetes和Tekton CI的可扩展工具和基础设施,以及复杂的测试用例生成和验证流程。: ~: { y9 Q! Y! `; j" `
9 f: ^2 m5 R: r& ^
RNGD张量收缩处理器代表了AI加速器技术的进步。通过专注于可持续计算并利用创新的硬件和软件优化,FuriosaAI创造了强大的解决方案,适用于大语言模型和生成式AI时代。随着对高效AI计算需求的持续增长,像RNGD这样的技术将在使先进AI能够应用于更广泛的场景并服务于更多用户方面发挥关键作用。& E# `8 {( Q$ B
6 E( u# y$ l$ h( y- l" n% z! E$ W4 ^* ~2 {9 T
参考文献$ N3 V, m7 V0 p) ]5 [. D
[1] J. Paik, "RNGD – Tensor Contraction Processor for Sustainable AI Computing," FuriosaAI Inc., 2024.
% U D6 H; m4 j, [/ Z: N) K. ^( f+ m
$ i. |$ ^ u. K6 R# t- END -! x9 \1 D7 E5 f' J
3 M* S1 b3 `. Q3 }1 Y软件申请我们欢迎化合物/硅基光电子芯片的研究人员和工程师申请体验免费版PIC Studio软件。无论是研究还是商业应用,PIC Studio都可提升您的工作效能。
2 c7 }6 s" r$ ~" [# E点击左下角"阅读原文"马上申请
" R0 s6 X4 q# Y. B" B
7 t0 D6 N, v& ?4 @; G7 O5 I欢迎转载1 W) n# N7 _4 K& N0 B
6 {" C' u" q3 P转载请注明出处,请勿修改内容和删除作者信息!
+ I6 y" O+ C9 Y& M X
! M4 v0 F7 o; Y# X5 [/ |5 | g' ?+ v$ ]8 v& G5 I! i4 u( j
7 W5 Y; [! X: H4 F4 r# g3 V
gv3vhov5rai64042711402.gif
 6 b& a1 F4 p; t* A f# ^
6 b& a1 F4 p; t* A f# ^
8 B7 ~/ O% B5 s4 M. j6 o- q: F
关注我们) [6 B7 H/ n# N) p) m% p
1 K; j7 D4 C; \) L, j" m# @" M
1 L5 g r, W4 N
yfnag5ly02464042711502.png

7 Q7 Z; r+ @8 x- }* N |
' p, {/ ~+ ]- i/ m
y1ml43djqh364042711602.png

" F/ w* f5 `& Y h% m |
# f+ ]4 H1 E, F/ r
nnjmle55o0364042711702.png
 * C$ d3 r3 \2 B W7 f2 G9 H
* C$ d3 r3 \2 B W7 f2 G9 H
|
. d3 b" i6 ~7 b9 o" c& ]( _; k4 [6 L# B) _2 q3 Z1 j5 Q
4 i& h G" P) a0 {4 ^) Q1 G
$ l- g# X& D2 s; H
关于我们:( p- H% ?# q# u5 z5 n8 [
深圳逍遥科技有限公司(Latitude Design Automation Inc.)是一家专注于半导体芯片设计自动化(EDA)的高科技软件公司。我们自主开发特色工艺芯片设计和仿真软件,提供成熟的设计解决方案如PIC Studio、MEMS Studio和Meta Studio,分别针对光电芯片、微机电系统、超透镜的设计与仿真。我们提供特色工艺的半导体芯片集成电路版图、IP和PDK工程服务,广泛服务于光通讯、光计算、光量子通信和微纳光子器件领域的头部客户。逍遥科技与国内外晶圆代工厂及硅光/MEMS中试线合作,推动特色工艺半导体产业链发展,致力于为客户提供前沿技术与服务。) v( m0 ` R2 U% Z
J0 \6 E. U4 i3 ~% B
http://www.latitudeda.com/) z; ?# }' k& z
(点击上方名片关注我们,发现更多精彩内容) | 
















 窥视卡
窥视卡

 置顶卡
置顶卡 变色卡
变色卡