|
|

引言$ w6 d* J: `8 ^6 w8 ?3 U
人工智能的快速发展对计算能力和能源效率提出了极高要求。随着人工智能模型日益复杂,计算需求显著增长,数据中心和边缘设备面临着巨大的供电挑战。本文探讨半导体技术领域的创新,阐述这些技术如何实现更高能效的人工智能架构[1]。
W+ i3 J0 u0 A1 O) v
4ho3vr522fd64016430637.png

9 G. \* C8 c, r! F& {1 m* k4 T
5 r1 Y" z: `) x; z6 e+ M/ _1
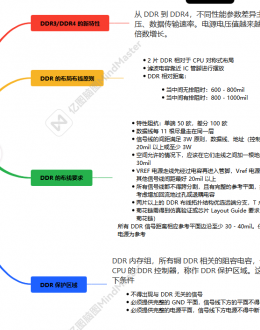
# A: T" G9 A4 ^. P: V, a先进内存集成与优化& B- o% A% c( s' E1 c( |
人工智能计算面临的基本挑战之一是实现内存与计算单元之间的高效数据传输。传统架构中,内存和计算部件相互分离,数据移动产生大量功耗开销。现代解决方案通过创新封装技术,将内存置于更靠近计算单元的位置。6 G+ f- y6 Y# I1 S4 ^
dsmkqgu5oi064016430738.png
 ! Z0 Q, e1 `8 X3 A4 c+ F$ \
! Z0 Q, e1 `8 X3 A4 c+ F$ \
图1:内存优化策略展示了从基准设计到高带宽内存(HBM)三维堆叠的演进过程,说明缩短内存与计算单元之间的距离并采用低功耗互连对提高功率效率的重要性。
7 D& |: t. q8 [
# ]+ e E- `9 c, ?; v7 T半导体行业开发了多种内存集成优化方案。从基准配置开始,制造商通过片上集成实现更大容量的缓存,最终发展到采用高带宽内存的先进三维堆叠技术。这种演进显示了向更高效内存架构迈进的明确方向。$ u' c0 d% C% }, a2 l
gccv0udm4jp64016430838.png
 r& k c5 m `7 D" r
r& k c5 m `7 D" r
图2:2.5D和3D内存堆叠方法的对比,展示了3D内存堆叠通过垂直集成实现额外的功耗节省和密度提升。7 H# i: H% e. K6 T
9 h5 U! Q0 f9 n! {从2.5D到3D堆叠技术的转变是内存集成的重大进步。2.5D技术使用硅中介层实现组件的水平连接,而3D堆叠技术能够直接在处理器核心上方实现DRAM层的垂直集成。这种垂直集成最大限度地减少了数据传输的物理距离,提高了功率效率和内存带宽。! @% x, h) N/ B4 M
c, X% @ t. Y; I5 Z
2
; x. I+ X2 P# k! z: y- _先进封装技术
( I1 }% ]5 L% A- ?9 A现代人工智能加速器需要精密的封装解决方案来高效集成各种组件。AMD的MI300系列展示了先进封装技术的突破,实现了基于Chiplet的复杂设计。该架构包含多个采用AMD CDNA 3计算单元的加速器复合裸片(XCD),与配备精密内存控制器和缓存系统的输入/输出裸片(IOD)协同工作。IOD集成了128通道HBM3接口和256MB Infinity Cache,提供了超高的内存带宽和效率。, x1 d+ ^7 q% C9 R' h
h2pnaytotvv64016430939.png
 - k% g) i: y" N/ }. ]
- k% g) i: y" N/ }. ]
图3:AMD MI300的先进架构展示了加速器复合裸片(XCD)、输入/输出裸片(IOD)和HBM3内存通过AMD Infinity Fabric技术的集成,实现了GPU和CPU Chiplet技术的高吞吐量统一。
+ `1 n: }% _- w# o) |5 j% V2 U3 S4 n$ T) w
Infinity Fabric互连技术构成了这一架构的核心,在保持功率效率的同时实现了组件之间的无缝通信。使用先进的3D和2.5D封装技术集成HBM3内存代表了内存子系统设计的重大进步。2.5D硅中介层技术在维持最佳功率特性的同时,实现了内存与计算裸片之间的高带宽连接。, d U# M, k# u: p3 m
y0otgebp1e464016431039.png
 ) ?% ?3 ~! M! }- r% n
) ?% ?3 ~! M! }- r% n
图4:MI300的详细框图显示了Infinity Cache在IOD上的分布情况,以及MI300X实际芯片图像,展示了各种组件的精密集成。
0 p% P% G! ?. i/ B6 l; w& l/ V: d, s' A$ G
MI300中的Infinity Cache实现展示了精密的分区和分布策略。缓存在四个IOD之间均匀分配,每个IOD的部分进一步细分为64个1MB tile,每个HBM通道配置两个tile。这种精细的组织结构通过局部化的数据移动实现了高效的数据访问模式,同时保持了功率效率。
5 C* X8 l- K' w. q1 J8 C, R' t$ O1 r* J; ^9 C6 a. N3 t9 S
3" r _$ h: e y- {, {. A$ m
制程技术优化
& a0 P- }5 s$ I4 t, N$ r" B5 L4 Y制程技术在实现能源效率方面发挥着关键作用。现代高性能计算实现通过创新的晶体管设计和电压调节方法,着重优化动态和静态功耗。阈值电压(Vth)和供电电压(Vdd)之间的相互作用带来了需要仔细管理的复杂优化挑战。( w$ _: K2 |+ T6 m/ k/ b
pixuygmybka64016431139.png

. ~* q7 A4 K" L* i( E图5:通过场效应晶体管Vth调节实现的功率优化图,展示了阈值电压、供电电压和能效优化之间的关系。
, ]" l3 `3 Q) ^; M" q2 N/ g! X; B @3 v3 \/ y) h) _: e
工程师必须仔细平衡各种参数以实现最佳功率效率。阈值电压与供电电压之间的关系展示了影响动态和静态功耗的复杂相互作用。较低的供电电压可以减少动态功耗,但这必须与维持足够的噪声容限和防止时序违规的需求取得平衡。阈值电压优化过程需要仔细考虑工艺变化、温度效应和可靠性要求。; d1 ] @3 X5 v5 _, u/ y. l
, N7 g/ R, e2 U( Y9 z% y$ {
45 Z3 W" w0 w# _5 v3 e o
先进三维集成
' n! ]" q6 F8 p# e* AAMD的3D V-Cache技术是先进三维集成技术的重大突破。这种创新方法采用直接铜对铜键合技术,消除了传统焊球,改善了电气和热特性。通过硅导通孔(TSV)技术实现了裸片之间的高带宽垂直连接,同时保持了信号完整性和功率效率。2 J2 L/ N/ Z% c# z) a8 I
dx3erfon2l464016431240.png

9 l5 ?; |4 t% r图6:AMD 3D V-Cache技术说明图展示了铜对铜"无凸点"设计和通过硅导通孔(TSV)的实现,展示了该技术如何推动密度和能效的领先地位。
7 D% D* d, y6 n, d0 g- }8 p( R+ c% B
该技术結合了结构性硅层,提供机械稳定性和改善的热特性。无凸点设计降低了整体堆叠高度,通过减少裸片之间的热阻提高了散热性能。这种精密的集成方法在保持功率效率的同时实现了缓存容量和带宽的显著提升。9 b# |- w5 Z# H$ x0 q
. ^0 ^# d8 D9 e" Q( e& x1 u, M
5% }9 _, d3 n8 d' `3 a
热管理和供电9 ^7 f4 {5 A! d" Q& G* D! ?7 ]0 Y
有效的热管理对维持高功率人工智能加速器的最佳性能至关重要。现代设计采用深沟槽电容,与传统平面电容相比提供了更优的电压跌落缓解能力。这些结构直接集成到硅中,提供局部电荷存储,帮助在高电流瞬态期间维持稳定的电压水平。; R% ?1 \: W. p
& O; k8 l6 ]! v7 B+ T& `1 h
先进的电源管理技术利用分布式传感器实时监测热状况和功耗。这些数据支持sophisticated的动态电压和频率调节算法,在保持安全工作温度的同时优化性能。采用改进导热性能的新型导热界面材料,可以更有效地将热量从裸片传递到散热器。2 i7 S- y9 N: J# i
, B0 R5 \8 I) P8 x: B6
e2 `. H2 ^) \1 _ r$ z未来发展方向. W& q d# k) _, B
半导体行业通过多项新兴技术持续推进能效计算的发展。光电共封装代表了提高数据中心应用网络带宽和能源效率的新方向。该技术将光收发器直接集成到处理器封装中,减少了高速数据传输所需的能量。5 I4 d( A# i: k/ r
- h7 l" A. G5 m3 y/ x8 i硅基光电子集成正在快速发展,开发将光互连集成到传统CMOS工艺的新技术。先进制程节点正在探索互补型场效应晶体管(CFET)技术,与传统晶体管设计相比,提供了改进的静电特性和减少的寄生电容。 ^9 G2 Y: a$ [" o& M4 s
5 T" G" V7 Z& i9 H# ?& Y正在开发用于缓存应用的新型存储技术,如自旋转移力矩磁性随机访问存储器(STT-MRAM),在保持高性能的同时提供了降低功耗的可能。这些新兴技术,结合封装和热管理方面的持续创新,将满足人工智能不断增长的计算需求,同时保持能源效率。
) C3 W5 X; k; @* T+ }: {' _, A! E/ Y* w B2 Q
参考文献, b5 I& }# |" S
[1] M. Fuselier, L. Bair, D. Kulkarni, G. Refai-Ahmed, J. Wuu, and O. Zia, "Advancing AI with Energy-Efficient Architectures: Innovations in Fab Process, Packaging, and System Integration," in 2024 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 2024.
! w# B. D) S$ g) U% U. iEND
8 J% U6 G3 h: p1 \9 U' \2 ^ J/ B( V4 O P; z4 D
软件申请我们欢迎化合物/硅基光电子芯片的研究人员和工程师申请体验免费版PIC Studio软件。无论是研究还是商业应用,PIC Studio都可提升您的工作效能。7 E; C# m# E% _* |& X
点击左下角"阅读原文"马上申请" O, I9 h2 P- |. ` \
* b- T7 o- H* D. x2 {. j+ [: A* r
欢迎转载9 Q+ ~- B" P" L) ? @
8 q! t- G! @" G [6 s" p Z+ |
转载请注明出处,请勿修改内容和删除作者信息!
- V: z. R% N, l4 c! _% X( Z, y4 ]; C+ P% b5 L' d+ i1 P' M7 X
9 Y: G/ H9 H; v9 o n L. Z. H
0 O6 g0 m- U4 [" A" A
fpndap4w5nz64016431340.gif
 + q' F5 h1 j, I
+ q' F5 h1 j, I
" s o; Q8 s' l: y- m1 W- ^关注我们
) [% R( T7 Y) ^+ d! F, l4 Q% H. {. o/ [
6 k. y0 ^0 L+ s# B1 F1 j$ U, l
sp4rnkbefpm64016431440.png

( H U" I. \% Q+ @- V8 j | % j5 _) U' E4 Q8 u1 \6 t
qtk1psoxtty64016431540.png

" R' H7 r, y" X( K& |6 n# C | / N! @- G, ]; n; I. P# \' ^6 o) [
gglkt1ikgvx64016431640.png

}) G" e# W; x, g% F% v( M |
3 e, Q( g! }: m* J: l( O
$ [) Y# A8 K; K6 [$ L
! r4 E4 _! v4 r; o! L) a# T
: m7 i6 m+ [6 N4 {2 l/ k2 u1 W关于我们:9 `% _0 Y' |& |
深圳逍遥科技有限公司(Latitude Design Automation Inc.)是一家专注于半导体芯片设计自动化(EDA)的高科技软件公司。我们自主开发特色工艺芯片设计和仿真软件,提供成熟的设计解决方案如PIC Studio、MEMS Studio和Meta Studio,分别针对光电芯片、微机电系统、超透镜的设计与仿真。我们提供特色工艺的半导体芯片集成电路版图、IP和PDK工程服务,广泛服务于光通讯、光计算、光量子通信和微纳光子器件领域的头部客户。逍遥科技与国内外晶圆代工厂及硅光/MEMS中试线合作,推动特色工艺半导体产业链发展,致力于为客户提供前沿技术与服务。: Z4 Q$ @4 p z4 t% U
7 m, Q) m6 Y+ y6 x% f6 X8 Y; S
http://www.latitudeda.com/
' _4 E( Y# h, m: i, y(点击上方名片关注我们,发现更多精彩内容) |
|

















 窥视卡
窥视卡

 置顶卡
置顶卡 变色卡
变色卡