|
50| 0

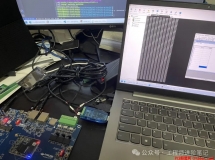
[AI芯片学习]-关于矩阵乘法和硬件加速的标杆性经典论文 |
| ||












Copyright ©2015-2022 长沙市凡亿教育科技有限公司 Powered by©Discuz! 技术支持:凡亿教育 ( 湘ICP备2024059722号 )



 置顶卡
置顶卡 变色卡
变色卡